|
Phemmer
|
Сообщение #1
4 июля 2013 в 23:07
|
Супермен 
71 |
Сделал анализ статистики клавогонщиков и делюсь несколькими интересными графиками. 1. Зависимость рекорда от средней скоростиТакой график уже есть на клавостате, но есть отличие - я вручную отсортировал накрученные результаты. Прежде всего это накрутка средней или количества ошибок с помощью недоездов и иных способов. Графики для игроков имеющих общий пробег от 3000 текстов и не менее 1000 в обычном  После отсеивания накруток тренд получился очень близок к точке (0,0) формула: РЕКОРД = 1,2748 * СРЕДНЯЯ - самая приближенная формула по которой можно посчитать приблизительный рекорд. Разброс от расчетного значения будет зависеть от таких факторов как ошибочность игрока, количество пробега и других факторов. То же самое, но без всякого отсеивания: скрытый текст…  формула: РЕКОРД = 1,189 * СРЕДНЯЯ + 38,39 На клавостате для такого графика предлагается линейный тренд. На мой взгляд зависимость лучше описывает экспоненциальный тренд. формула: ОШИБКИ = 4.84769*e^(-0.00254 * СО); СО - средняя скорость в обычном. 3. Зависимость процента ошибок от общего пробега. Ось пробега в логарифмическом виде наглядно выглядит. Тренд тоже логарифмический. На мой взгляд вообще, ошибочность зависит от общего пробега более явно, чем от достигнутой скорости. Это не только пробег на клавогонках, а и практика в реальности. Разница в скорости при одинаковом пробеге объясняется прежде всего разницей в возрасте начала обучения слепого метода. Но для дальнейшего анализа этот тренд не взял, ведь кто-то пришел с нулевым пробегом на клавогонки, кто-то со значительным. Вернемся к самой первой зависимости, РЕКОРД = 1,2748 * СРЕДНЯЯ Посмотрим как влияют на коэффициент К=РЕКОРД/СРЕДНЯЯ такие параметры: 4. Влияние процента ошибок на коэффициент К (рекорд/средняя)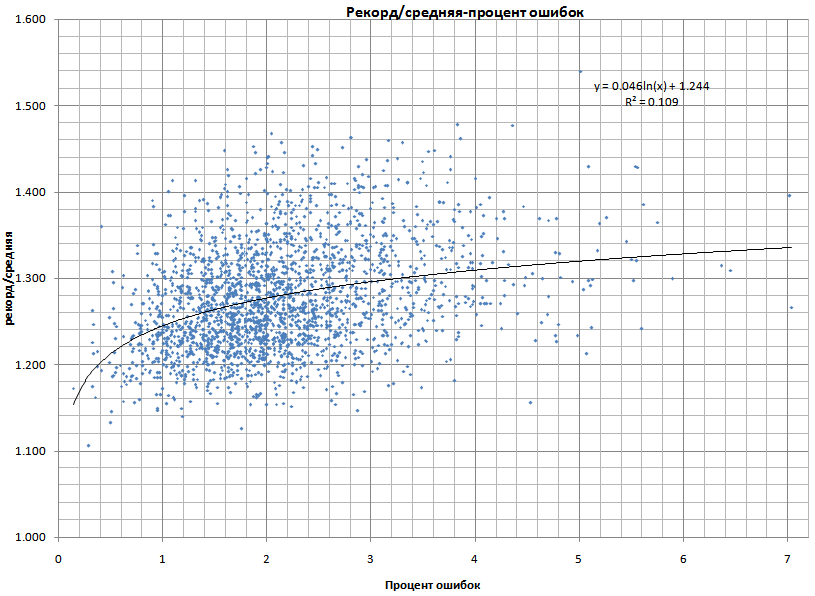 Тот же график в логарифмическом масштабе оси ошибок Тренд наблюдается: чем больше ошибок, тем выше рекорд, но среднее количество ошибок для разных рангов разное. Тогда вычислим отношение реального процента ошибок к ожидаемому. Ожидаемое - п.2 - Зависимость процента ошибок от средней скорости. Так избавляемся от разброса ошибочности по рангам, чтобы общая формула получилась всеранговая. 5. Влияние отношения реального процента ошибок к ожидаемому на коэффициент К (рекорд/средняя) Тренд логарифмический То же самое в логарифмическом масштабе ошибок: 6. Влияние пробега в обычном режиме на коэффициент К (рекорд/средняя)Увеличение пробега кроме роста средней скорости, которое само по себе повлияет на рекорд, дает больше шансов поймать удобный текст и больше шансов не ошибиться на таком тексте. В этом заключается его влияние на коэффициент К (рекорд/средняя). Масштаб пробега и тренд логарифмический.  7. 7. Если принять как базу зависимость РЕКОРД = 1,2748 * СРЕДНЯЯ, добавить влияние степени ошибочности для данной скорости и количество пробега выраженное в увеличении или в уменьшении коэффициента К = 1,2748 на слагаемые, получается следующая формула для расчета вероятного рекорда: P=C*(1,11555+0,05804*LN(A/(4,85158*EXP(-0,00254*C)))+0,0191*LN(B))P - наиболее вероятный рекорд в обычном C - реальная средняя скорость в обычном (без накруток) A - средний процент ошибок в обычном (также без накруток) B - пробег в обычном Для удобства сделал небольшой онлайн-калькулятор для расчета.скрытый текст… Все коэффициенты здесь есть на графиках кроме 1,11555. Он получился так: 1,11555=1.2748-((1.2748-1.1147)+(1.2748-1.27565))
Среднеквадратичное отклонение для формулы составляет 19,29 зн/мин, тогда как для формулы Р=1,2748*С — 21,74 зн/мин от реальных рекордов
Если раскрыть скобки получится такой вид этой формулы: P=C*(1.02326+0.0001484*C+0.05844*ln(A)+0.0191*ln(B)) На рекорд также будет оказывать влияние пробега в частотных словарях - известно, что в рекордных текстах много частотных слов, метод набора - раскладка, жесткие или динамические зоны - у многих набирающих динамикой рекорд выше ожидаемого. А также еще другие факторы. Если у вас по калькулятору получилась вероятный рекорд больше вашего, возможно это говорит о потенциале. Если ниже - возможно вы ввели необъективные или завышенные исходные числа. Насчет количества пробега - недоезды с целью выбивания хороших результатов тоже стоит прибавлять в формулу в " B - пробег в обычном" - хоть это не пробег а "недобег". Второй способ определения вероятного рекорда. (добавлено из сообщения 39) Многие замечали, что распределение результатов езды в обычном режиме режиме, да и не только в обычном, похоже на нормальное распределение – распределение, которое часто встречается в природе. Такое распределение описывается строго заданной функцией, и это можно использовать, чтобы посчитать вероятность выпадения результатов в каком-то промежутке. Распределение результатов получается близким к нормальному, когда результат является суммой многих случайных слабо взаимозависимых величин, каждая из которых вносит малый вклад и отсутствуют факторы, в отдельности сильно влияющие на общий результат. К последним факторам не относятся ошибки в процессе набора, но к ним относятся: недоезды, с целью фильтрации каких-либо результатов, также когда что-то постороннее отвлекло во время набора, будь то выскочившее окно, заход в заезд уже после старта, пробегающий по столу или клавиатуре кот ;) и т.д. Как это использовать. 1. Посчитать свое распределение реальных результатов, например из экспорта статистики в xls файл (требуется премиум), то есть взять какой-то период и посчитать, сколько раз выпала каждая скорость. Построить диаграмму распределения скоростей, оценить, насколько распределение похоже на нормальное. 2. Определить параметры, которые задают функцию нормального распределения на этом промежутке, то есть математическое ожидание (=средняя арифметическая скорость), стандартное (среднеквадратическое) отклонение или дисперсию - меру разброса результатов от математического ожидания. Это можно сделать в экселе соответствующими функциями. 3. Задать новую функцию нормального распределения по этим двум найденным параметрам и найти вероятность выпадения интересующих результатов. Мы рассматриваем какой-то пробеговый промежуток, например пробег за последние N тысяч текстов. И если хотим найти наиболее вероятный рекорд - то считаем и определяем такой диапазон скорости, чтобы вероятность нахождения в нем равнялась одному заезду. (для рекорда ведь нужен всего один заезд ;)) ПримерБерем промежуток 7000 текстов Подсчитываем количество заездов по каждой скорости (например от 200 до 600 с шагом 1) Получаем такое распределение (синие точки): 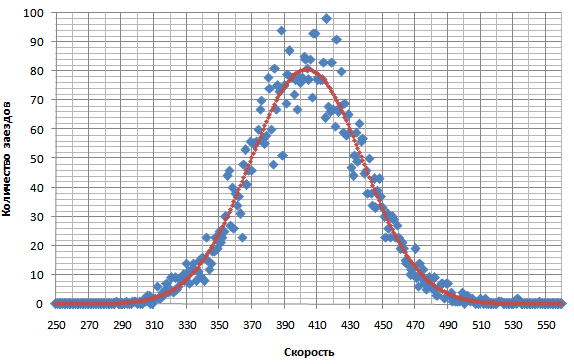 Пока не очень ясно, сильно ли отличается от нормального. Усредняем каждую скорость по шести соседним, получаем:  Вот это уже весьма похоже. Отклонения не большие. Красным цветом показан график распределения, установленный по рассчитанным параметрам из реального распределения: математическое ожидание=403,6, стандартное отклонение - 34,6. Находим область, в которой по этому распределению должен содержаться всего один заезд, это очень просто сделать интегрированием ;) : Получается область рекорда – 529+, то есть от [529 до бесконечности ;)) Но наиболее вероятно он выпадет в районе 535 10% шансов – 550+. Тут я еще раз подчеркиваю что это метод расчета не точного рекорда для всех и каждого, а наиболее вероятного.Способ должен работать не только для обычного режима, а и для всех остальных режимов тоже. Но нужен достаточный пробег (хотя бы от тысячи текстов) Вопрос: Какую область пробега лучше взять? Ответ: Любую, но она должна быть похожа по графику на нормальное распределение, не иметь больших провалов в каких-то областях, особенно в последней, предрекордной. Общая рекомендация такая: взять область начиная с того момента, как средняя скорость выросла где-то на 30 знаков. Попробовав разные варианты, обнаружил что результат получается похожим, даже если брать отрезки с разной начальной точкой. Если взять более раннюю точку отсчета, средняя скорость на тот момент была меньше, но общее число заездов становится больше - поэтому результат похож. Для всех случаев нужно стремиться чтобы максимально совпала вот эта область:  Недоездунам, которые фильтруют неудачные заезды, тоже можно определить вероятный рекорд таким способом, только выбрать параметры функции нормального распределения нужно будет вручную, так, чтобы добиться максимального сходства в этой предрекордной области. Получится что-то вроде этого: 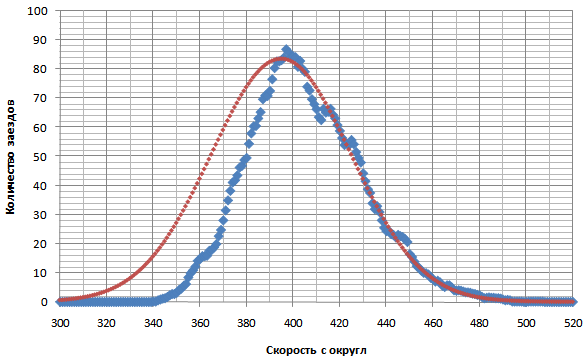 Область между красной и синей линией в левой части графика - это область, попавшая под недоезды. Аналогичное делается если вы доезжаете все доезды, включая провальные по другим причинам, кроме причины ошибок - (когда что-то постороннее отвлекло во время набора): подбирается параметры функции нормального распределения, чтобы последняя часть графика совпала, тогда будет не "выемка" в медленной области а "наплыв". Связь с первым способом определения вероятного рекорда.По влиянию пробега в обычном - совпадение способов хорошее. В первом способе была зависимость Р = (0,019*LN(B) + 1,114)*C. Коэффициенты 0,019 и натуральный логарифм пробега дают очень хорошую схожесть с подсчетом влияния пробега из нормального распределения. А коэффициент 1,114 будет коррелировать со стандартным отклонением. Если бы было прислано много статистик, можно было б отследить это влияние. Как я проверял: устанавливаем жестко среднюю скорость, ст. отклонение. Ставим первоначальный пробег. Подбираем коэффицицент вместо 1,114 такой, чтобы вероятные рекорды совпали. Потом меняем пробег сколько угодно в разумных пределах - и вероятные рекорды будут очень хорошо совпадать. Еще из закона распределения следует важный вывод. Поскольку график симметричен, хорошие результаты будут встречаться с такой же частотой как и плохие. Например, если вы достигаете скорости (средняя+80 зн) один заезд каждый день, то раз в день выпадет заезд (средняя-80 зн). Это абсолютно нормально для процесса набора. Последний раз отредактировано 15 ноября 2013 в 11:31 пользователем Phemmer
|
|
Котанчик
|
Сообщение #2
4 июля 2013 в 23:23
|
Маньяк 
43 |
541.98 - ну что ж, посмотрим  Хотя даже в Спринте пока столько не сделал!
|
|
Maxonik
|
Сообщение #3
4 июля 2013 в 23:41
|
Экстракибер 
77 |
Наиболее вероятный рекорд 623
|
|
_еретик_
|
Сообщение #4
5 июля 2013 в 09:46
|
Супермен 
31 |
Эвеланш, Максоник, вы точно по этой формуле считали? P=C*(1,11555+0,05804*LN(A/(4,85158*EXP(-0,00254*C)))+0,0191*LN(B))
P - наиболее вероятный рекорд в обычном
C - реальная средняя скорость в обычном (без накруток)
A - средний процент ошибок в обычном (также без накруток)
B - пробег в обычном
|
|
Переборыч
|
Сообщение #5
5 июля 2013 в 11:16
|
Клавомеханик-Организатор событий 
55 |
Кроме первого графика, больше нигде не увидел закономерностей. С таким мизерным коэффициентом достоверности (R 2) соотношение показателей просто не имеет смысла. На клавостате о подобном честно сказано, например: Линейный тренд для успехов не является достоверным. Phemmer писал(а): C - скорость без накруток
A - %-т ошибок без накруток А как убрать накрутки? У zenz'а, например: Средняя 741 - накрутки = 630 реальной средней. Но как?
|
|
Maxonik
|
Сообщение #6
5 июля 2013 в 13:03
|
Экстракибер
77 |
Еретик я калькулятор использовал
|
|
sav1
|
Сообщение #7
5 июля 2013 в 14:25
|
Маньяк 
43 |
На самом деле средняя на КГ не та самая средняя от 1-го заезда. Всегда было интересно как она считается, и насколько близко это к оценке реально средней. Интересно слышать мнения или видеть пруфлинк. Результаты калькулятора скрытый текст… 570. М-м-м.. сомневаюсь, но обнадеживает :-) А вобще для 600 мне надо: либо догнать среднюю на каких-то +25, либо увеличить ошибок до 4%, либо накатать на текущем уровне еще +165 000 обычек. Первый пункт полегче, второй очень соблазнителен, а третий остается на черный день  з.ы. все это прикол конечно, а автору респект за наглядность и инструмент. з.з.ы. на самом деле мой случай не средний, сейчас я в обычки хожу только погонять на славу, а использую массу словарей и не абы как. Хотя признаю что надо ходить и просто так, в расслабоне. Последний раз отредактировано 5 июля 2013 в 14:30 пользователем sav1
|
|
GoodLoki
|
Сообщение #8
5 июля 2013 в 14:25
|
Новичок 
30 |
Phemmerно есть отличие - я вручную отсортировал накрученные результаты. Это называется не отсортировал, а подогнал к желаемым результатам. Очень советую почитать эту главу: Из книги «Вы, конечно, шутите, мистер Фейнман!»Ну и как результат калькулятор врёт. Причём чем больше скорость, тем больше ошибка. Вот попробовал посчитать для тех профилей, где я уверен, в честности результатов, и в отсутствии накруток. Alkhor: Средняя скорость: 222 зн./мин. Ошибки: 1.77% Пробег: 936 Рекорд: 254 зн./мин. калькулятор: 271 зн./мин. Ошибка калькулятора: +6.6% GoodLoki: Средняя скорость: 338 зн./мин. Ошибки: 1.52% Пробег: 2044 Рекорд: 393 зн./мин. калькулятор: 420 зн./мин. Ошибка калькулятора: +6.9% Экспериментатор: Средняя скорость: 436 зн./мин. Ошибки: 1.92% Пробег: 2200 Рекорд: 504 зн./мин. калькулятор: 555 зн./мин. Ошибка калькулятора: +10% дядя_Паша: Средняя скорость: 430 зн./мин. Ошибки: 1.84% Пробег: 3243 Рекорд: 500 зн./мин. калькулятор: 555 зн./мин. Ошибка калькулятора: +11%
|
|
AcidMan
|
Сообщение #9
5 июля 2013 в 14:28
|
Кибергонщик 
48 |
Нифига себе я наркоман)) Наиболее вероятный рекорд при проценте моих максимально-средних ошибок и минимално средней скорости в обычном (515 и 1.3% ошибок) скорость составляет 665 а если прям идеал взять возможностей (средняя 520 и ошибок 1.15), то немного более 670 где-то. Так я давно об этом знал, прикольная штука ребят) надо сделать этот рекорд)
|
|
sav1
|
Сообщение #10
5 июля 2013 в 14:38
|
Маньяк
43 |
Avalanche писал(а): GoodLoki писал(а): AcidMan писал(а): Полагаю что если с вошедших в анализ профилей взять стату по другим словарям, где есть наработка минимум под сотню, и как-то припилить к расчету (причем с разными коэффициентами в зависимости от словаря), то картина может быть ближе. Еще ближе будет, если выяснить и использовать очередность и коэффициент пробегов в них. Как это делать - уже не знаю 
|
|
Phemmer
|
Сообщение #11
5 июля 2013 в 16:33
|
Супермен
71 |
Переборыч писал(а): Кроме первого графика, больше нигде не увидел закономерностей. С таким мизерным коэффициентом достоверности (R2) соотношение показателей просто не имеет смысла. На клавостате о подобном честно сказано, например: Мизерный, но тенденции видны. Чем больше ошибочность и пробег, тем вероятный рекорд выше. На клавостате только для одного последнего графика признано что линейный тренд не достоверен, а для графиков "Зависимость процента ошибок от средней скорости" и "Зависимость средней скорости от пробега" взяты линейные тренды которые хуже моих логарифмических. Переборыч писал(а): А как убрать накрутки? У zenz'а, например: Средняя 741 - накрутки = 630 реальной средней. Но как? GoodLoki писал(а): Это называется не отсортировал, а подогнал к желаемым результатам. Мне интересно было посмотреть статистику исходя из реальных результатов, а не "средненакрученных" Накрученные статистики в основном просто удалял из обработки. Пусть это называется "На своё усмотрение" какие удалять. Сделаете свою формулу - тогда сравним у кого точнее. Некоторые результаты при высоких скоростях вытягивал чтобы оставит больше результатов в быстром диапазоне. Как - пусть тоже называется "на своё усмотрение" и опять же - предлагаете свой метод и результаты - сравним. sav1 писал(а): На самом деле средняя на КГ не та самая средняя от 1-го заезда. Всегда было интересно как она считается, и насколько близко это к оценке реально средней. Интересно слышать мнения или видеть пруфлинк. Пруфлинка нет, но где-то писалось что средняя и скорости и ошибок в обычных (ненулевых) областях зависит только от последних 50-ти заездов. Я вкладываю в понятие "реальная средняя скорость" такой смысл - покатайте обычный режим со 100 % доездов в течение пары дней в разное время суток и в разных состояниях пальцев (до полной усталости не доводить) в сумме заездов 50-100. Получите в профиле величину близкую к вкладываемой в понятие. Или если все время доезжаете, посмотрите свой на график колебания средней, найдите ту скорость вокруг которой происходят ее колебания. GoodLoki писал(а): Ну и как результат калькулятор врёт. Причём чем больше скорость, тем больше ошибка. Калькулятор неправильно считает? Проверил, всё нормально, полное совпадение с excel. Например, для HRUST средняя была 690, 1,53% ошибок, 87908 текстов. По екселю О.Р.=944, по калькулятору - 943.73. Ну в реале у него меньше немного, может потенциал есть еще. GoodLoki писал(а): Вот попробовал посчитать для тех профилей, где я уверен, в честности результатов, и в отсутствии накруток. дядя_Паша/Экспериментатор - это нестандартный случай, переучивание на другую раскладку, к тому же у него была цель - выбить 500 на каждом профиле, поэтому я могу усомниться что он всё доезжал. Повторюсь, формула считает наиболее вероятный рекорд а не точный для каждого. Чем ближе условия к усредненным - тем должно быть точнее, например, стандартные зоны фыва олдж, желательно равномерный пробег без скачков, перерывов, переучиваний, минимум смен клавиатур. У вас с Alkhor значит есть потенциал обновить рекорды. С момента как на твоем графике скорость поднялась на 10 знаков имеешь очень малый пробег - рекорду неоткуда появиться без пробега, его надо ловить. Плюс опять нестандартные раскладки. sav1 писал(а): Полагаю что если с вошедших в анализ профилей взять стату по другим словарям, где есть наработка минимум под сотню, и как-то припилить к расчету (причем с разными коэффициентами в зависимости от словаря), то картина может быть ближе. Еще ближе будет, если выяснить и использовать очередность и коэффициент пробегов в них. Как это делать - уже не знаю Я не приплетал в формулу общий пробег. Как общий пробег повлияет на рекорд в обычном? Только усилит навык - повысит среднюю скорость или понизит число ошибок - что и так уже учтено. Единственное, как я уже говорил, что может повлиять – пробег в частотных словарях.
|
|
Переборыч
|
Сообщение #12
5 июля 2013 в 16:59
|
Клавомеханик-Организатор событий
55 |
Phemmer писал(а): Накрученные статистики в основном просто удалял из обработки. Пусть это называется "На своё усмотрение" какие удалять. Сделаете свою формулу - тогда сравним у кого точнее. Некоторые результаты при высоких скоростях вытягивал чтобы оставит больше результатов в быстром диапазоне. Как - пусть тоже называется "на своё усмотрение" и опять же - предлагаете свой метод и результаты - сравним. Для сравнения нужны исходные данные и твой метод рафинирования. Например, указываешь: однократно отсекаются крайние 5% (в целях очистки явно "глючных" рекордов и нарочито апатичной средней). Тогда исследование можно воссоздать, сравнить и предложить лучшие варианты очистки, помимо "некоторые значения не приглянулись, а другие взял с потолка". :) Последний раз отредактировано 5 июля 2013 в 16:59 модератором Переборыч
|
|
Phemmer
|
Сообщение #13
5 июля 2013 в 17:21
|
Супермен
71 |
Переборыч,
Метод рафинирования только вручную. Сортируем по всем интересным показателям, смотрим крайние значения, кликаем профиль, смотрим график → принимаем решение. Проходим по всем показателям пока не надоест, до какого-то процента отсева, пока останутся только статистики похожие на реальные.
Типичные случаи: график заканчивается резким скачком средней скорости, на графике есть рекорды - "столбы", нормальный график на всем протяжении заканчивается внезапным снижением средней скорости (есть и такие).
|
|
ЦАРЬ
|
Сообщение #14
5 июля 2013 в 17:57
|
Супермен 
62 |
1,2748*423=539.2404 В моём случае формула достаточно точна) особенно учитывая, что рекорд в 544 сделал совсем недавно, 4 дня назад, а до этого было 540 А с помощью онлайн калькулятора вообще получилось 545.138 Впечатляет, разница в 1 от рекорда, Phemmer, ты крут! твоя система работает) Последний раз отредактировано 5 июля 2013 в 19:50 пользователем ЦАРЬ
|
|
ЙФЯУ9
|
Сообщение #15
5 июля 2013 в 18:01
|
Новичок 
36 |
Последний раз отредактировано 21 сентября 2017 в 20:47 пользователем ЙФЯУ9
|
|
Fenex
|
Сообщение #16
5 июля 2013 в 18:08
|
Клавомеханик 
49 |
У меня совпадает. Интересно.
Надо бы состряпать расчёт в профилях с помощью userjs.
|
|
GoodLoki
|
Сообщение #17
5 июля 2013 в 18:56
|
Новичок
30 |
Phemmerдядя_Паша/Экспериментатор - это нестандартный случай, переучивание на другую раскладку, к тому же у него была цель - выбить 500 на каждом профиле, поэтому я могу усомниться что он всё доезжал.
Повторюсь, формула считает наиболее вероятный рекорд а не точный для каждого. Чем ближе условия к усредненным - тем должно быть точнее, например, стандартные зоны фыва олдж, желательно равномерный пробег без скачков, перерывов, переучиваний, минимум смен клавиатур.
У вас с Alkhor значит есть потенциал обновить рекорды. С момента как на твоем графике скорость поднялась на 10 знаков имеешь очень малый пробег - рекорду неоткуда появиться без пробега, его надо ловить. Плюс опять нестандартные раскладки. Ну тогда бы и написал: «Для среднестатистического клавогонщика, набирающего в „ЙЦУКЕН“». А то понимаешь, калькулятор, на «научной основе». Хотя в любом случае не одобряю отбрасывания результатов, не подходящих под «теорию». Если результаты отбрасываются, то должно быть железное доказательство, что они недостоверны. Ну и в противовес тогда, должны проверяться достоверность, тех результатов, которые принимаются. Надеюсь почитал главу по ссылке. Там очень интересно, про эксперимент Милликена написано. Считать, что-то на основе принципиально не проверяемой статистике, достаточно сомнительно. А уж считать что-то на этой-же статистике, но ещё и с произвольно обрезанными результатами, это просто шоу. Но как шоу, может быть интересно.
|
|
Speedyman
|
Сообщение #18
5 июля 2013 в 19:54
|
Тахион 
70 |
Ввел свою реальную среднюю - 550 зн./мин., 29к пробега, 2% реальных ошибок - и получился тот рекорд, который у меня есть сейчас - 737. Последний раз отредактировано 5 июля 2013 в 19:55 пользователем Speedyman
|
|
ЙФЯУ9
|
Сообщение #19
5 июля 2013 в 20:07
|
Новичок
36 |
Последний раз отредактировано 21 сентября 2017 в 20:48 пользователем ЙФЯУ9
|
|
Phemmer
|
Сообщение #20
5 июля 2013 в 20:53
|
Супермен
71 |
Владимир2о18 писал(а): Я вот только одного не понимаю. Как рекорд связан одновременно и с пробегом, и со средней, если средняя никак не зависит от пробега. Есть математические выкладки?
Фактически средняя считается за последние N текстов, то есть всё, что было до N, можно просто отбросить, а следовательно цифра пробега к данной ситуации вообще не должна иметь никакого отношения. C - реальная средняя скорость в обычном (без накруток), а не та, которая висит в профиле за последние 50 текстов. Свою среднюю каждый точнее оценит сам. Непосредственно от пробега никак не зависит. Цифра пробега B отражает следующее: Увеличение пробега ... дает больше шансов поймать удобный текст. То, что за время этого пробега еще возрастет средняя скорость, учтется не в коэффициенте В, а в С - средней скорости. Как рекорд связан одновременно и с пробегом, и со средней – это график 6, тренд от которого пошел в итоговую формулу. Владимир2о18 писал(а): Если формула действительно работает, то оптимальнее будет рассчитывать по ней не рекорд, а среднюю из рекорда. Поясни, что такое 'средняя из рекорда' ?
|




