|
ЙФЯУ9
|
Сообщение #21
6 июля 2013 в 08:48
|
Новичок 
36 |
Последний раз отредактировано 21 сентября 2017 в 20:50 пользователем ЙФЯУ9
|
|
Disobey
|
Сообщение #22
6 июля 2013 в 11:33
|
Кибергонщик 
42 |
Владимир2о18 писал(а): А следовательно единственная объективная статистика - это именно рекорд (при достаточном пробеге, конечно). Значит из рекорда можно вывести с помощью твоей формулы и реальную среднюю, и это будет намного объективнее, чем вычислять из ненастоящей средней скорости в профиле ненастоящий предполагаемый рекорд. В формуле ещё процент ошибок присутствует, который тоже накручивается, так что не посчитать.
|
|
ЙФЯУ9
|
Сообщение #23
6 июля 2013 в 11:47
|
Новичок
36 |
Последний раз отредактировано 21 сентября 2017 в 20:51 пользователем ЙФЯУ9
|
|
Phemmer
|
Сообщение #24
6 июля 2013 в 14:25
|
Супермен 
71 |
Владимир2о18 писал(а): Если мы исходим из того, что формула правильная и даёт ошибку с очень малой погрешностью, то обратная формула для *реальной средней скорости*, выведенной из настоящего-текущего рекорда, будет тоже объективна. Да, обратную формулу вывести можно. Но обратное вычисление представляет меньший интерес. Рекорд изменяется не плавно, а скачкообразно - скачки бывают 10-20 знаков и более. И 0x2 прав, как правило при накрутках средней накручивается и процент ошибок. Процент ошибок весомо влияет на результат. Результатом для средней будет решение квадратного уравнения: 0.0001484*C^2+(1.02326+0.05844*ln(A)+0.0191*ln(B))*С-P=0Но если задаться такой целью, можно брать не рекорд, а среднее из пяти лучших результатов, исследовать те же зависимости, поменять коэффициенты в формулах - так будет намного точнее, чем один рекорд.
|
|
Cheatah
|
Сообщение #25
7 июля 2013 в 03:10
|
Маньяк 
16 |
Очень классно, мне нравится. Предлагаю сделать гадалку типа "сколько мне осталось до следующего ранга", в котором можно было бы ввести эти данные и показывалось бы, сколько надо пробега или сколько надо плюса к средней, чтобы перейти к следующему рангу. Причем просить желающих "погадать" вводить именно показатели реальных условий, например замеряя среднюю за 50 заездов без недоездов (на свежесозданном профиле или обнулив при помощи Премиума) + указывать реальную оценку пробега (к примеру, если человек несколько профилей использует). Заодно получится более точные данные собрать, возможно. Насчет формулы расчета средней - она пересчитывается так после каждого заезда, начиная с двенадцатого (ЕМНИП): НС = СС+(РЕЗ-СС)*0.02 здесь НС - новая средняя, СС - старая средняя, РЕЗ - результат заезда. Таким образом, выходит, что на среднюю наиболее сильно влияет последний заезд, предыдущий меньше и т. п., а то, что было на 50 заездов раньше, влияет уже в пренебрежимо малой степени (но все же чуть-чуть влияет). Аналогичная формула используется для среднего процента ошибок. До 12-го заезда средняя считается иначе, кажется там коэффициент не 0.02 а что-то вроде 1/n, где n = номер заезда. Но тут могу ошибаться, давно не проверял. Это все легко проверить при помощи Excel и таблицы собственных результатов. P.S. Кстати, интересно было бы сравнить это с английскими показателями для QWERTY и других раскладок. Последний раз отредактировано 7 июля 2013 в 03:13 пользователем Cheatah
|
|
дядя_Паша
|
Сообщение #26
8 июля 2013 в 17:01
|
Супермен 
2 |
Спасибо за работу! Мне понравилось. Теперь обсуждение. Сразу оговорюсь, что мою критику не следует воспринимать как симпатию/антипатию к кому-либо. Это просто некоторые мысли, пришедшие в голову. Сначала по графикам. 1. ОК. Без отсеивания я бы тоже провел через точку (0;0). А то средняя 0, а рекорд не ноль, как-то нефизично. 2. ОК. Там можно что хочешь ставить. Я бы попробовал еще степенную зависимость. Еще дело в том, что Эксель проводит в данном случае только двухпараметрическую аппроксимацию. Но может же еще быть и постоянная составляющая (или, что хуже, линейная комбинация двух функций). Т.е. любой математический пакет в помощь. 3. ОК. Только картина безрадостная: чтобы снизить процент ошибок на 0,2%, нужно пробег увеличить в 2 раза. 4. Непонятно, почему логарифмический вид. Но, наверное, до этого были испытаны разные типы трендов. И я бы сказал в конце: чем больше % ошибок, тем меньше средняя по отношению к безошибочному рекорду. 5. ОК. Хорошо приведено (в смысле, преобразовано из п.4 в п.5): ошибки в норме - 1, могут быть отклонения в ту или иную сторону от нормы (для данной скорости), что приводит к изменению коэффициента К. 6. ОК. Это не только шанс поймать удобный текст (для этого хватит и 100 текстов), а еще и шанс поймать психологическое состояние, тренировка разгона, "заточка" мозгов и пальцев именно под данную длину текста - 200-300 символов. А вообще, нужно более детальный анализ проводить, ведь из этого графика не исключен рост средней скорости. А чем выше средняя, тем дисперсия результатов больше. И возможно, она растет нелинейно от средней скорости (я про дисперсию графика в обычном в профилях) Phemmer писал(а): На рекорд также будет оказывать влияние пробега в частотных словарях ...... недоезды ....... тоже стоит прибавлять .... Если мы рассматриваем рекорд в обычном режиме, то и тексты, наверное, нужно учитывать, похожие на обычные - короткие тексты, книги, мини-марафон, марафон. Только с понижающими коэффициентами, т.к. длина у них отличается. В целом очень хвалю, работа огромная проделана (серьезно что ли сидел, проверял тысячи профилей?? тогда респект еще больший). И есть практическое применение. Дальше по комментариям остальных отписавшихся. Переборыч писал(а): Кроме первого графика, больше нигде не увидел закономерностей. С таким мизерным коэффициентом достоверности (R2) соотношение показателей просто не имеет смысла. На клавостате о подобном честно сказано, например:
Линейный тренд для успехов не является достоверным. На практике обычно используется не только коэффициент корреляции, а и его произведение на число точек. Это произведение не должно быть меньше некоторого числа. Для разных задач - разное. Для анализа биржевых данных я встречал число ~10 (В.Нидерхоффер, Л.Кеннер - Практика биржевых спекуляций). Здесь это точно соблюдается (для 10), и притом с большим запасом. И просто по виду корреляционного поля тоже можно сказать, если оно не в форме размытого круга, а вытянуто в каком-то направлении (под углом к горизонтали и вертикали), то зависимость точно есть, пусть не строго функциональная (для нее коэффициент был бы 1). Просто данные не слишком устойчивые. sav1 писал(а): На самом деле средняя на КГ не та самая средняя от 1-го заезда. Всегда было интересно как она считается, и насколько близко это к оценке реально средней. Интересно слышать мнения или видеть пруфлинк. http://klavogonki.ru/forum/general/269/page1/#post8GoodLoki писал(а): попробовал посчитать для тех профилей, где я уверен, в честности результатов, и в отсутствии накруток. На Экспериментаторе в обычном был большой перерыв, я катал книги, отчетливо видно, что график не логарифмической формы, а ступенчатый. Т.е. данные о пробеге сильно занижены. На дяде Паше после первого 500, в самом конце, есть некоторое число недоездов, т.е. надо брать среднюю пониже знаков на 10-20. Или кусочек в конце просто "отрезать". Phemmer писал(а): дядя_Паша/Экспериментатор - это нестандартный случай, переучивание на другую раскладку Кривая обучения новому навыку (или новой раскладке, или прыжкам в длину, или плевкам в высоту) будет такой же формы во всех случаях - сначала быстрый рост, потом его замедление. При одинаковой интенсивности прикладываемых усилий. sav1 писал(а): взять стату по другим словарям, где есть наработка минимум под сотню, и как-то припилить к расчету Да, можно. Об этом написал выше. Лучше по словарям, похожий на обычный и где общее затраченное время достаточно велико. Т.е. если не на порядок и более отличается от обычного. Phemmer писал(а): Мизерный, но тенденции видны. Да, общий вид корреляционного поля в каждом случае как раз говорит об этом. Переборыч писал(а): Например, указываешь: однократно отсекаются крайние 5% Да, как раз так очень часто делается в статистике - крайние слева и справа отбрасываются (очень большие и очень малые). Но, возможно, здесь формализовать более сложно, поэтому делается "на глаз": Phemmer писал(а): только вручную , т.к. четких однозначных критериев нет. Кстати, например, сглаживание данных "на глаз" часто используется. И оно бывает намного лучше всех известных алгоритмов фильтрации - выделяет существенное, отсеивает "фон". Fenex писал(а): Надо бы состряпать расчёт в профилях с помощью userjs. Наверное, пока рановано. Пусть побольше народу отпишется в теме - по совпадениям/несовпадениям. Возможно, сам автор еще чего-нибудь додумает. GoodLoki писал(а): Если результаты отбрасываются, то должно быть железное доказательство, что они недостоверны. К сожалению, в большинстве реальных ситуаций "железных" критериев нет. Пусть у нас есть ряд измерений одной величины в каких-то единицах: 11, 10, 11, 10,5, 12, 11, 10, 9, 10, 12,5, 20. Последняя явно выбивается из ряда. Нужно проанализировать, почему так получилось. А если бы на месте 20 стояло, например, 14,5, то нужно использовать какие-то критерии, которые, максимум, что позволяют - утверждать границы вероятности, с которой данное измерение достоверно (в помощь, например, методические инструкции - "Обработка результатов измерений с многократными наблюдениями"). Но чем "размазаннее" критерии, тем больше вероятность потенциальной ошибки, с этим я согласен. Поэтому нужно экспериментальное подтверждение выведенного правила/закона - работает/не работает. Вообще, по итогу - для меня самое существенное - честная средняя, рекорд (безошибочный, естественно), и процент ошибок для честной средней. И после этого среднюю можно привести к любому проценту ошибок, если известна цена ошибки для конкретной скорости. Например, для 400 это, допустим, 5-8 знаков, для 500 - 10 знаков, 600 - 15-20, ну и так далее. Т.е., допустим, у меня в цифрах средняя 560 и процент ошибок 0,7% (лень заглядывать, это чисто по памяти), у Корнера - 550 и 1,6% соответственно. 1 ошибка на длине 300 символов - это 0,3%. Пусть эта ошибка равна 12 знакам на скорости 550. 1,6%-0,7%=0,9%. 0,9/0,3=3 ошибки. 550+3*12=586. 586 зн/мин - такая средняя получилась бы у него гипотетически, если он снизил процент ошибок в статистике до 0,7%. Ну и 586 больше 560, т.е. он существенно сильнее :)
|
|
дядя_Паша
|
Сообщение #27
8 июля 2013 в 17:02
|
Супермен
2 |
Блин, вторую страницу не посмотрел ( ее комментировать уже не буду.
|
|
Phemmer
|
Сообщение #28
10 июля 2013 в 00:03
|
Супермен
71 |
дядя_Паша писал(а): 3. ОК. Только картина безрадостная: чтобы снизить процент ошибок на 0,2%, нужно пробег увеличить в 2 раза. Да уж. Если прикинуть какой пробег за плечами у Автандилины - на клавогонках она имеет наименьшее количество ошибок (0,15) - по тренду - около 12 млн текстов! (в расчет на средний текст, пусть приблизительно равен длине обычке). Правда если оценить реальный возможный пробег - по 300 эквиваленто-обычек в день в течении пяти дней в неделю в течение пусть сорока лет - выходит около 3 млн текстов.  Видимо понадобилось меньше чем 12 млн потому что многие в моей статистике пришли на клавогонки уже с каким-то пробегом. Или способ обучения другой, тоже вероятно. дядя_Паша писал(а): Если мы рассматриваем рекорд в обычном режиме, то и тексты, наверное, нужно учитывать, похожие на обычные - короткие тексты, книги, мини-марафон, марафон. Только с понижающими коэффициентами, т.к. длина у них отличается. Не думаю что пробег в других режимах как-то влияет на рекорд непосредственно через количество пробега. Можно хоть сколько угодно катать что угодно, но пока не зайдешь в обычку, рекорд в ней не поменяется)). И что самое главное - общая тренировка навыка вольется в увеличение средней скорости, которое уже учтено. Другое дело - частотные словари. рекордные тексты - это тексты как правило с большим содержанием частотных слов. Средняя скорость вообще из чего состоит (грубо) - из скорости, которая переводится во время, потраченное на сложные слова плюс время потраченное на легкие (частотные) слова. Легких слов всегда меньше по количеству, однако их высокая встречаемость может поставить их наравне по количеству встретившихся в тексте. Допустим первый вариант: мы налегаем на проработку сложных сочетаний, проблемных зон, периферии, а частотные словари не катаем - мы достигнем роста первой составляющей а вторая останется на уровне близком к первой. Получится большая стабильность результатов - рекорд будет не таким высоким. Другой вариант - мы налегаем на частотные словари. Вторая составляющяя - будет проработана сильно, первая останется на обычном уровне (ниже, чем в первом варианте. таком чтобы средняя скорость осталась равна в обоих вариантах). Получим более высокий рекорды в текстах, содержащим много частотных слов. А такие тексты попадутся. Так что только пробег в частотных и ни в чем другом будет влиять на коэффициент К. При желании можно проанализировать эту зависимость если собрать соответствующую базу. Правда, на примере Автандилины видно, что есть предел этому. Возможно по количеству общего пробега. У нее в обычном и в частотном показатели отличаются очень мало. дядя_Паша писал(а): В целом очень хвалю, работа огромная проделана (серьезно что ли сидел, проверял тысячи профилей?? тогда респект еще больший). И есть практическое применение. Отсеяно почти 300 профилей, значит просмотрено около 400-500. Да, все вручную. дядя_Паша писал(а): Кривая обучения новому навыку (или новой раскладке, или прыжкам в длину, или плевкам в высоту) будет такой же формы во всех случаях - сначала быстрый рост, потом его замедление. При одинаковой интенсивности прикладываемых усилий. Интересно понаблюдать за прогрессом тех, кто сначала умел набирать на одной раскладке, а потом на другой, и на другой значительно впоследствии превысил результаты первой, не будет ли там ступеньки или существенного замедления в районе максимальной скорости на первой. Еще по влиянию метода набора: жесткие зоны/динамические. Полагаю, что набирающие динамикой будут иметь больший коэффициент К. Ведь разногласий надеюсь нет, что у динамики потенциал выше. И в первую очередь он раскрывается на наиболее частых сочетаниях, наиболее частых словах. Тех которые по жестким зонам набирать сложнее. А дополнительно катая частотные словари усиливается этот эффект. И сам, пожалуй, выскажусь по совпадению/несовпадению. У меня реальный рекорд выше чем ожидаемый на ~20 знаков. Предполагаю, это объясняется использованием динамического метода набора. Последний раз отредактировано 10 июля 2013 в 00:48 пользователем Phemmer
|
|
дядя_Паша
|
Сообщение #29
10 июля 2013 в 08:45
|
Супермен
2 |
Phemmer писал(а): Если прикинуть какой пробег за плечами у Автандилины Ой-ей-ей. Даже думать страшно ))) Здесь, думаю, процент ошибок сам будет уменьшаться лишь до определенного уровня, например, 0,8%-1%. А дальше нужны уже сознательные усилия для печати на безошибочность. Соответственно, это уменьшает разгон. Но если дорос до того уровня, который практически применим, и уменьшил число ошибок до минимума, то зачем менять эту ситуацию? Здесь просто не спортивная печать, а практически ориентированная. Phemmer писал(а): Можно хоть сколько угодно катать что угодно, но пока не зайдешь в обычку, рекорд в ней не поменяется)) Ага :) но одно дело, если ты пошел в нее, например, с нулевым пробегом вообще, и другое - если откатал несколько сотен отрывков по книгам или мини-марафонам. Во-первых, печатать будешь намного увереннее. Другое дело, что разгон именно на данной длине не будет слишком впечатляющим. Но зато будет более широкий диапазон текстов для небольшого рекорда ) Phemmer писал(а): Допустим первый вариант: мы налегаем на проработку сложных сочетаний, проблемных зон, периферии, а частотные словари не катаем - мы достигнем роста первой составляющей а вторая останется на уровне близком к первой. Получится большая стабильность результатов - рекорд будет не таким высоким.
Другой вариант - мы налегаем на частотные словари. Вторая составляющяя - будет проработана сильно, первая останется на обычном уровне (ниже, чем в первом варианте. таком чтобы средняя скорость осталась равна в обоих вариантах). Получим более высокий рекорды в текстах, содержащим много частотных слов. А такие тексты попадутся.
Так что только пробег в частотных и ни в чем другом будет влиять на коэффициент К. При желании можно проанализировать эту зависимость если собрать соответствующую базу. Логика хорошо прослеживается в твоих рассуждениях. Согласен с тем, что частотные словари тоже помогут развить эту "пиковость", таким путем убивается 2 зайца - адаптируешься к той же длине текста, отрабатываешь легкие слова на более высокой, чем в обычном, скорости. Но если катать только частотку, и в обычку ходить раз в десятилетие, то обычный тоже не сильно сдвинется. Все-таки обычка далеко не на легких словах держится, даже рекордная. Phemmer писал(а): Так что только пробег в частотных и ни в чем другом будет влиять на коэффициент К Не-не. Ну почему так категорично? :) любой пробег - это ведь тоже пробег и его нельзя сбрасывать со счетов. Я думаю, что режимы большей длины/сложности способствуют, конечно, росту средней и стабильности, и тому, что рекорд не будет завален. ОК. Но разгон они уменьшают. Может быть, их влияние на величину ожидаемого рекорда будет отрицательным? Phemmer писал(а): Полагаю, что набирающие динамикой будут иметь больший коэффициент К. Ведь разногласий надеюсь нет, что у динамики потенциал выше. И в первую очередь он раскрывается на наиболее частых сочетаниях, наиболее частых словах. Тех которые по жестким зонам набирать сложнее. А дополнительно катая частотные словари усиливается этот эффект. Да, возможно. У динамики потенциал выше на раскладках, где по стандартным зонам один палец подряд может делать несколько нажатий подряд. На других не очень существенный выигрыш. Но есть в любом случае. А вообще, такое понятие, как "средняя скорость" - оно очень туманное (малоформализуемое) и день ото дня может прыгать знаков на +-30 и более. В зависимости от психологического/физического состояния, каких-то других причин. С другой стороны, рекорд - это в некотором смысле уникальное событие, выбивающееся из ряда. Анализировать рекорды может быть делом неблагодарным. Вот, например, есть человек со средней скоростью 600, он зашел на психологическом подъеме, хорошо выспался, день был успешным, пару текстов он разгоняется, видит - пальцы летают хорошо и точно. И тут он выбивает рекорд 800. Хотя..... это не сильно противоречит К=1,27 :) 800/600=1,33. Посему кажется, что 1,27 - это очччень хороший коэффициент. И, по поводу отсеивания, зрительно видно из пп.1,2, что в первом случае ты как бы "обрезал" крайние варианты сверху и снизу, отстоящие слишком далеко от предполагаемой зависимости рекорд-средняя. Может, это как раз и укладывается в те 5%, про которые говорил Переборыч. Ну или 10%. И можно будет формализовать этот этап.
|
|
Phemmer
|
Сообщение #30
10 июля 2013 в 16:29
|
Супермен
71 |
дядя_Паша писал(а): Может быть, их влияние на величину ожидаемого рекорда будет отрицательным? Да, они могут дать стабильности и влияние их на коэффициент может быть и отрицательным. Но сколь-нибудь отследить эти зависимости на основе существующих статистик я не представляю как. Упрощенно можно считать, что они снизят ошибочность, что и даст в существующей формуле отрицательное влияние на К. дядя_Паша писал(а): А вообще, такое понятие, как "средняя скорость" - оно очень туманное (малоформализуемое) и день ото дня может прыгать знаков на +-30 и более. В зависимости от психологического/физического состояния, каких-то других причин. Проблемы нет. Можно взять среднюю арифметическую скорость за 200-300 текстов (начиная от ранга профи). Можно провести усредняющую прямую, глядя на колебания графика реальной средней скорости за последнее время. Кстати формула будет работать и для режимов подобных режиму "Обычный" - неповторяющиеся тексты длиной около 240 символов, такие же количества знаков препинания, заглавных букв, длины слов. Например, " Обычный in English", "обычный" на других языках. дядя_Паша писал(а): И, по поводу отсеивания, зрительно видно из пп.1,2, что в первом случае ты как бы "обрезал" крайние варианты сверху и снизу, отстоящие слишком далеко от предполагаемой зависимости рекорд-средняя. Может, это как раз и укладывается в те 5%, про которые говорил Переборыч. Ну или 10%. И можно будет формализовать этот этап. А если так формализовать основное правило отсева: отсеиваем, если последняя часть графика скорости сильно отличается от экспоненциального роста и разброс в последней части сильно отличается от нормального распределения. Что есть сильно, что есть нормально - определить коэффициентами.
|
|
batkovich
|
Сообщение #31
25 июля 2013 в 15:54
|
Супермен 
54 |
Феммер, а как ты собираешься среднюю вычитывать свою? ты же учти то что в квалификации твоя скорость падает. иначе говоря средняя может быть плюс минус 10-15 процентов, если ты часто играешь в квалификацию или постоянно попадаешь под нее.)
|
|
Phemmer
|
Сообщение #32
25 июля 2013 в 16:37
|
Супермен
71 |
batkovich писал(а): Феммер, а как ты собираешься среднюю вычитывать свою? ты же учти то что в квалификации твоя скорость падает. иначе говоря средняя может быть плюс минус 10-15 процентов, если ты часто играешь в квалификацию или постоянно попадаешь под нее.) Я уже писал как ее определить постом выше. Проблемы нет. Можно взять среднюю арифметическую скорость за 200-300 текстов (начиная от ранга профи). Можно провести усредняющую прямую, глядя на колебания графика реальной средней скорости за последнее время. Что касается квалификации, это другой режим. Отличаются цели и метод езды. И брать среднюю с учетом большого влияния пробега в режиме квалификация будет неправильно для формулы расчета. скрытый текст… Мне чтобы подтвердить рекорд хватало всего пары доездов в квалификации. Неудачные попытки в ней я доезжать смысла не вижу. А пара результатов не испортит статистику
|
|
Phemmer
|
Сообщение #33
29 октября 2013 в 16:55
|
Супермен
71 |
 Нужны xls файлы экспорта статистики (премиум) обычного режима клавогонщиков для продолжения исследования и проверки еще одного способа определения вероятного рекорда. Требования: доезд более 90% текстов, активная езда в обычном режиме в последнее время, минимум резких смен клавиатур и переучиваний. xls файлы направляйте мне.
|
|
sav1
|
Сообщение #34
30 октября 2013 в 16:33
|
Маньяк 
43 |
Phemmer писал(а): активная езда в обычном режиме в последнее время, минимум резких смен клавиатур и переучиваний Фэйлы по всем трем требованиям, а так бы с удовольствием. Последний раз отредактировано 30 октября 2013 в 16:33 пользователем sav1
|
|
BI-FI-Car
|
Сообщение #35
30 октября 2013 в 19:37
|
Маньяк 
40 |
Нужны xls файлы ... для продолжения исследования
...
Требования: доезд более 90% текстов исследование на пяти файлах? 
|
|
Нимфоманиаче
|
Сообщение #36
31 октября 2013 в 00:54
|
Маньяк 
37 |
Воспользовалась калькулятором, показал рекорд один в один по сегодняшнему рейтингу за день.  
|
|
Phemmer
|
Сообщение #37
31 октября 2013 в 01:07
|
Супермен
71 |
BI-FI-Car писал(а): исследование на пяти файлах? Не понял вопроса. По одному xls-файлу от каждого добровольца. На них и исследование.
|
|
Переборыч
|
Сообщение #38
31 октября 2013 в 07:25
|
Клавомеханик-Организатор событий 
55 |
Полагаю, имелось ввиду, что Премиумы - сплошь недоездуны. Я так не считаю.
|
|
Phemmer
|
Сообщение #39
14 ноября 2013 в 10:19
|
Супермен
71 |
Второй способ определения вероятного рекорда.Многие замечали, что распределение результатов езды в обычном режиме режиме, да и не только в обычном, похоже на нормальное распределение – распределение, которое часто встречается в природе. Такое распределение описывается строго заданной функцией, и это можно использовать, чтобы посчитать вероятность выпадения результатов в каком-то промежутке. Распределение результатов получается близким к нормальному, когда результат является суммой многих случайных слабо взаимозависимых величин, каждая из которых вносит малый вклад и отсутствуют факторы, в отдельности сильно влияющие на общий результат. К последним факторам не относятся ошибки в процессе набора, но к ним относятся: недоезды, с целью фильтрации каких-либо результатов, также когда что-то постороннее отвлекло во время набора, будь то выскочившее окно, заход в заезд уже после старта, пробегающий по столу или клавиатуре кот ;) и т.д. Как это использовать. 1. Посчитать свое распределение реальных результатов, например из экспорта статистики в xls файл (требуется премиум), то есть взять какой-то период и посчитать, сколько раз выпала каждая скорость. Построить диаграмму распределения скоростей, оценить, насколько распределение похоже на нормальное. 2. Определить параметры, которые задают функцию нормального распределения на этом промежутке, то есть математическое ожидание (=средняя арифметическая скорость), стандартное (среднеквадратическое) отклонение или дисперсию - меру разброса результатов от математического ожидания. Это можно сделать в экселе соответствующими функциями. 3. Задать новую функцию нормального распределения по этим двум найденным параметрам и найти вероятность выпадения интересующих результатов. Мы рассматриваем какой-то пробеговый промежуток, например пробег за последние N тысяч текстов. И если хотим найти наиболее вероятный рекорд - то считаем и определяем такой диапазон скорости, чтобы вероятность нахождения в нем равнялась одному заезду. (для рекорда ведь нужен всего один заезд ;)) ПримерБерем промежуток 7000 текстов Подсчитываем количество заездов по каждой скорости (например от 200 до 600 с шагом 1) Получаем такое распределение (синие точки): 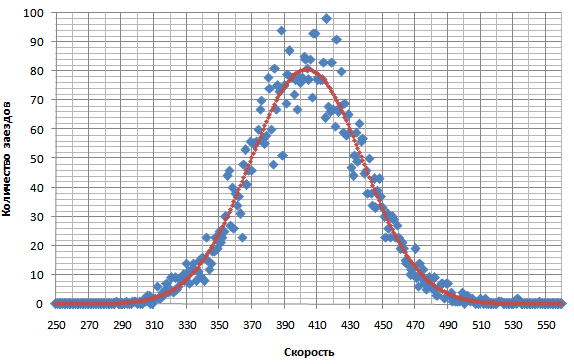 Пока не очень ясно, сильно ли отличается от нормального. Усредняем каждую скорость по шести соседним, получаем:  Вот это уже весьма похоже. Отклонения не большие. Красным цветом показан график распределения, установленный по рассчитанным параметрам из реального распределения: математическое ожидание=403,6, стандартное отклонение - 34,6. Находим область, в которой по этому распределению должен содержаться всего один заезд, это очень просто сделать интегрированием ;) : Получается область рекорда – 529+, то есть от [529 до бесконечности ;)) Но наиболее вероятно он выпадет в районе 535 10% шансов – 550+. Тут я еще раз подчеркиваю что это метод расчета не точного рекорда для всех и каждого, а наиболее вероятного.Способ должен работать не только для обычного режима, а и для всех остальных режимов тоже. Но нужен достаточный пробег (хотя бы от тысячи текстов) Вопрос: Какую область пробега лучше взять? Ответ: Любую, но она должна быть похожа по графику на нормальное распределение, не иметь больших провалов в каких-то областях, особенно в последней, предрекордной. Общая рекомендация такая: взять область начиная с того момента, как средняя скорость выросла где-то на 30 знаков. Попробовав разные варианты, обнаружил что результат получается похожим, даже если брать отрезки с разной начальной точкой. Если взять более раннюю точку отсчета, средняя скорость на тот момент была меньше, но общее число заездов становится больше - поэтому результат похож. Для всех случаев нужно стремиться чтобы максимально совпала вот эта область:  Недоездунам, которые фильтруют неудачные заезды, тоже можно определить вероятный рекорд таким способом, только выбрать параметры функции нормального распределения нужно будет вручную, так, чтобы добиться максимального сходства в этой предрекордной области. Получится что-то вроде этого: 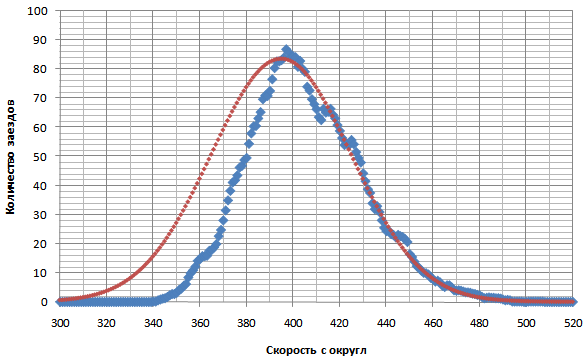 Область между красной и синей линией в левой части графика - это область, попавшая под недоезды. Аналогичное делается если вы доезжаете все доезды, включая провальные по другим причинам, кроме причины ошибок - (когда что-то постороннее отвлекло во время набора): подбирается параметры функции нормального распределения, чтобы последняя часть графика совпала, тогда будет не "выемка" в медленной области а "наплыв". Связь с первым способом определения вероятного рекорда.По влиянию пробега в обычном - совпадение способов хорошее. В первом способе была зависимость Р = (0,019*LN(B) + 1,114)*C. Коэффициенты 0,019 и натуральный логарифм пробега дают очень хорошую схожесть с подсчетом влияния пробега из нормального распределения. А коэффициент 1,114 будет коррелировать со стандартным отклонением. Если бы было прислано много статистик, можно было б отследить это влияние. Как я проверял: устанавливаем жестко среднюю скорость, ст. отклонение. Ставим первоначальный пробег. Подбираем коэффицицент вместо 1,114 такой, чтобы вероятные рекорды совпали. Потом меняем пробег сколько угодно в разумных пределах - и вероятные рекорды будут очень хорошо совпадать. Еще из закона распределения следует важный вывод. Поскольку график симметричен, хорошие результаты будут встречаться с такой же частотой как и плохие. Например, если вы достигаете скорости (средняя+80 зн) один заезд каждый день, то раз в день выпадет заезд (средняя-80 зн). Это абсолютно нормально для процесса набора. Отчет в формате xls с примером. Если кто с экселем не дружит, присылайте статистику, я вам посчитаю что получится.
|
|
Frostegg
|
Сообщение #40
14 ноября 2013 в 10:58
|
Супермен 
28 |
Раз снова всплыла тема... Тоже решил воспользоваться онлайн-калькулятором.  За расчет брал среднюю на данный момент, но недоездов столь много, она меньше на 10-15 пунктов( если бы доезжал 100%). Рекорд =646, ЗАЯВЛЕННЫЙ= 627)) Я особенный) Последний раз отредактировано 14 ноября 2013 в 10:56 пользователем Frostegg
|




